Implements import from the [callgrind format](https://www.valgrind.org/docs/manual/cl-format.html). This comes with a big caveat that the call graph information contained with callgrind formatted files don't uniquely define a flamegraph, so the generated flamegraph is a best-effort guess. Here's the comment from the top of the main file for the callgrind importer with an examplataion: ``` // https://www.valgrind.org/docs/manual/cl-format.html // // Larger example files can be found by searching on github: // https://github.com/search?q=cfn%3D&type=code // // Converting callgrind files into flamegraphs is challenging because callgrind // formatted profiles contain call graphs with weighted nodes and edges, and // such a weighted call graph does not uniquely define a flamegraph. // // Consider a program that looks like this: // // // example.js // function backup(read) { // if (read) { // read() // } else { // write() // } // } // // function start() { // backup(true) // } // // function end() { // backup(false) // } // // start() // end() // // Profiling this program might result in a profile that looks like the // following flame graph defined in Brendan Gregg's plaintext format: // // start;backup;read 4 // end;backup;write 4 // // When we convert this execution into a call-graph, we get the following: // // +------------------+ +---------------+ // | start (self: 0) | | end (self: 0) | // +------------------+ +---------------| // \ / // (total: 4) \ / (total: 4) // v v // +------------------+ // | backup (self: 0) | // +------------------+ // / \ // (total: 4) / \ (total: 4) // v v // +----------------+ +-----------------+ // | read (self: 4) | | write (self: 4) | // +----------------+ +-----------------+ // // In the process of the conversion, we've lost information about the ratio of // time spent in read v.s. write in the start call v.s. the end call. The // following flame graph would yield the exact same call-graph, and therefore // the exact sample call-grind formatted profile: // // start;backup;read 3 // start;backup;write 1 // end;backup;read 1 // end;backup;write 3 // // This is unfortunate, since it means we can't produce a flamegraph that isn't // potentially lying about the what the actual execution behavior was. To // produce a flamegraph at all from the call graph representation, we have to // decide how much weight each sub-call should have. Given that we know the // total weight of each node, we'll make the incorrect assumption that every // invocation of a function will have the average distribution of costs among // the sub-function invocations. In the example given, this means we assume that // every invocation of backup() is assumed to spend half its time in read() and // half its time in write(). // // So the flamegraph we'll produce from the given call-graph will actually be: // // start;backup;read 2 // start;backup;write 2 // end;backup;read 2 // end;backup;write 2 // // A particularly bad consequence is that the resulting flamegraph will suggest // that there was at some point a call stack that looked like // strat;backup;write, even though that never happened in the real program // execution. ``` Fixes #18
🔬speedscope
A fast, interactive web-based viewer for performance profiles. An alternative viewer for FlameGraphs. Will happily display multi-megabyte profiles without crashing your browser.
Given raw profiling data, speedscope allows you to interactively explore the data to get insight into what's slow in your application, or allocating all the memory, or whatever data is represented in the profiling data.
Usage
Visit https://www.speedscope.app, then either browse to find a profile file or drag-and-drop one onto the page. The profiles are not uploaded anywhere -- the application is totally in-browser.
Command line usage
For offline use, or convenience in the terminal, you can also install speedscope via npm:
npm install -g speedscope
Invoking speedscope /path/to/profile will load speedscope in your default browser.
Self-contained directory
If you don't have npm or node installed, you can also download a
self-contained version from https://github.com/jlfwong/speedscope/releases.
After you download the zip file from a release, simply unzip it and open the
contained index.html in Chrome or Firefox.
Supported file formats
speedscope is designed to ingest profiles from a variety of different profilers for different programming languages & environments. Click the links below for documentation on how to import from a specific source.
- JavaScript
- Ruby
- Python
- Go
- Rust
- Native code
- Importing from Instruments.app (macOS)
- Importing from
perf(linux)
- Importing from .NET Core
- Importing from GHC (Haskell)
- Importing from custom sources
Contributions to add support for additional formats are welcome! See issues with the "import source" tag.
Importing via URL
To load a specific profile by URL, you can append a hash fragment like #profileURL=[URL-encoded profile URL]&title=[URL-encoded custom title]. Note that the server hosting the profile must have CORS configured to allow AJAX requests from speedscope.
Views
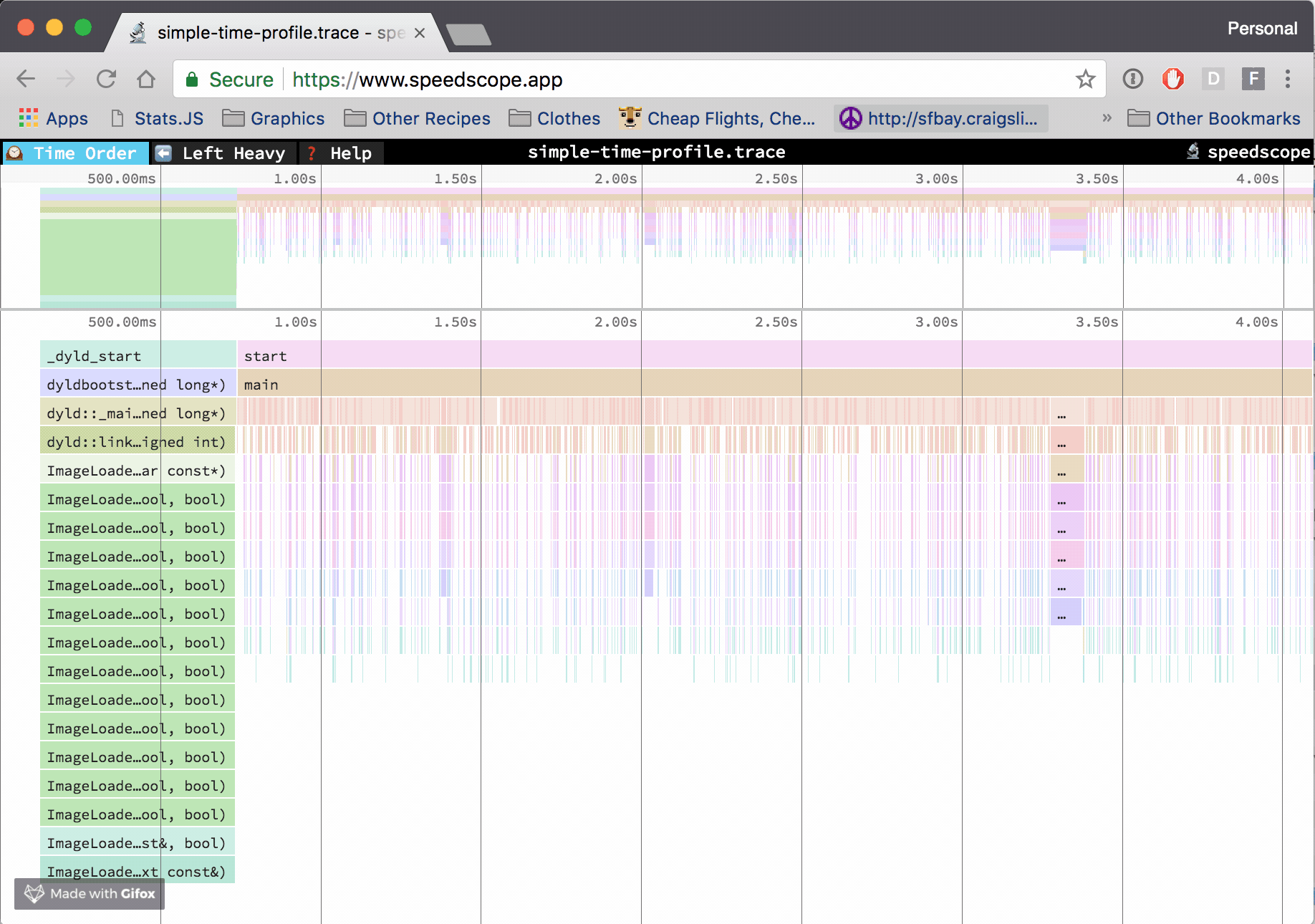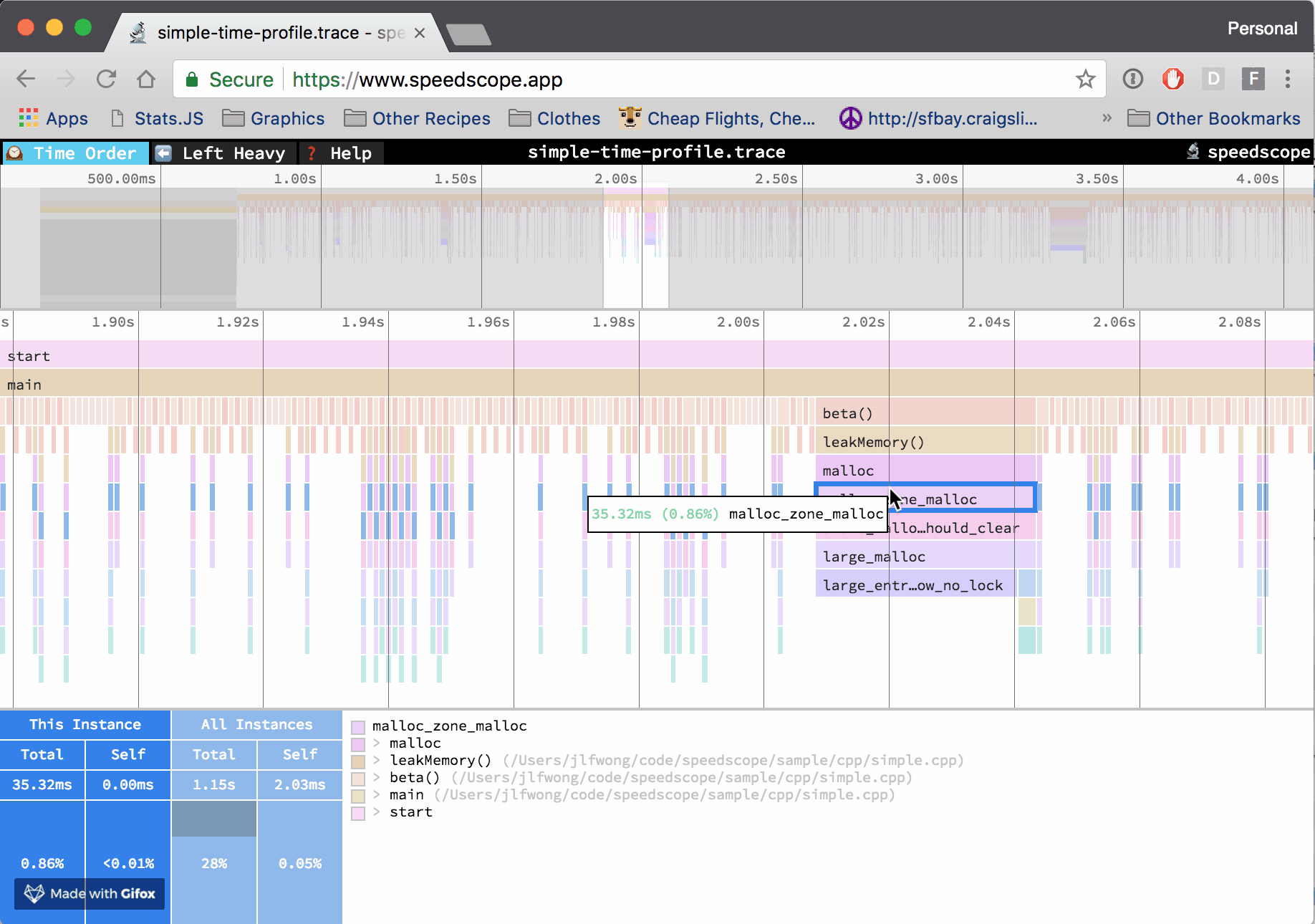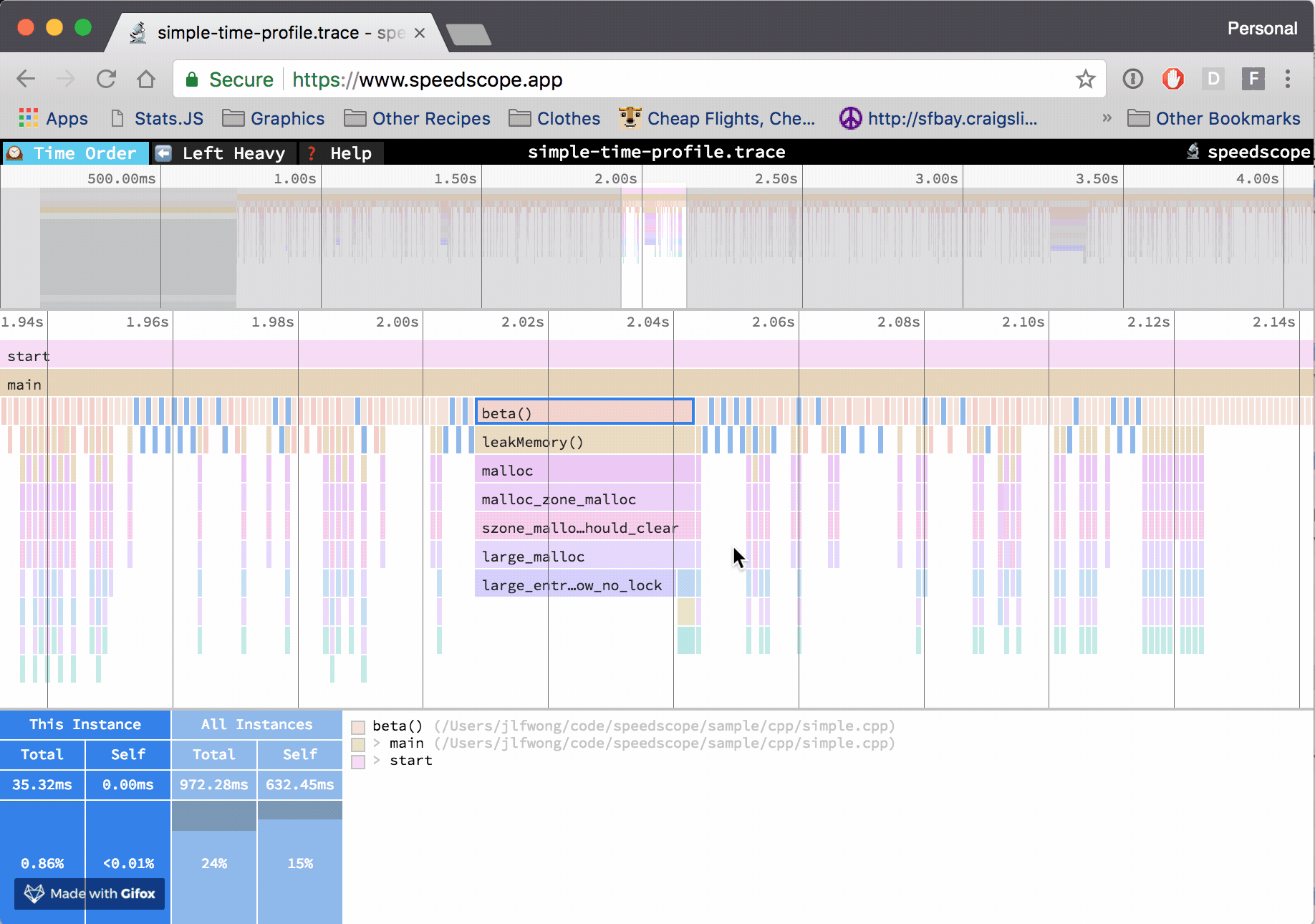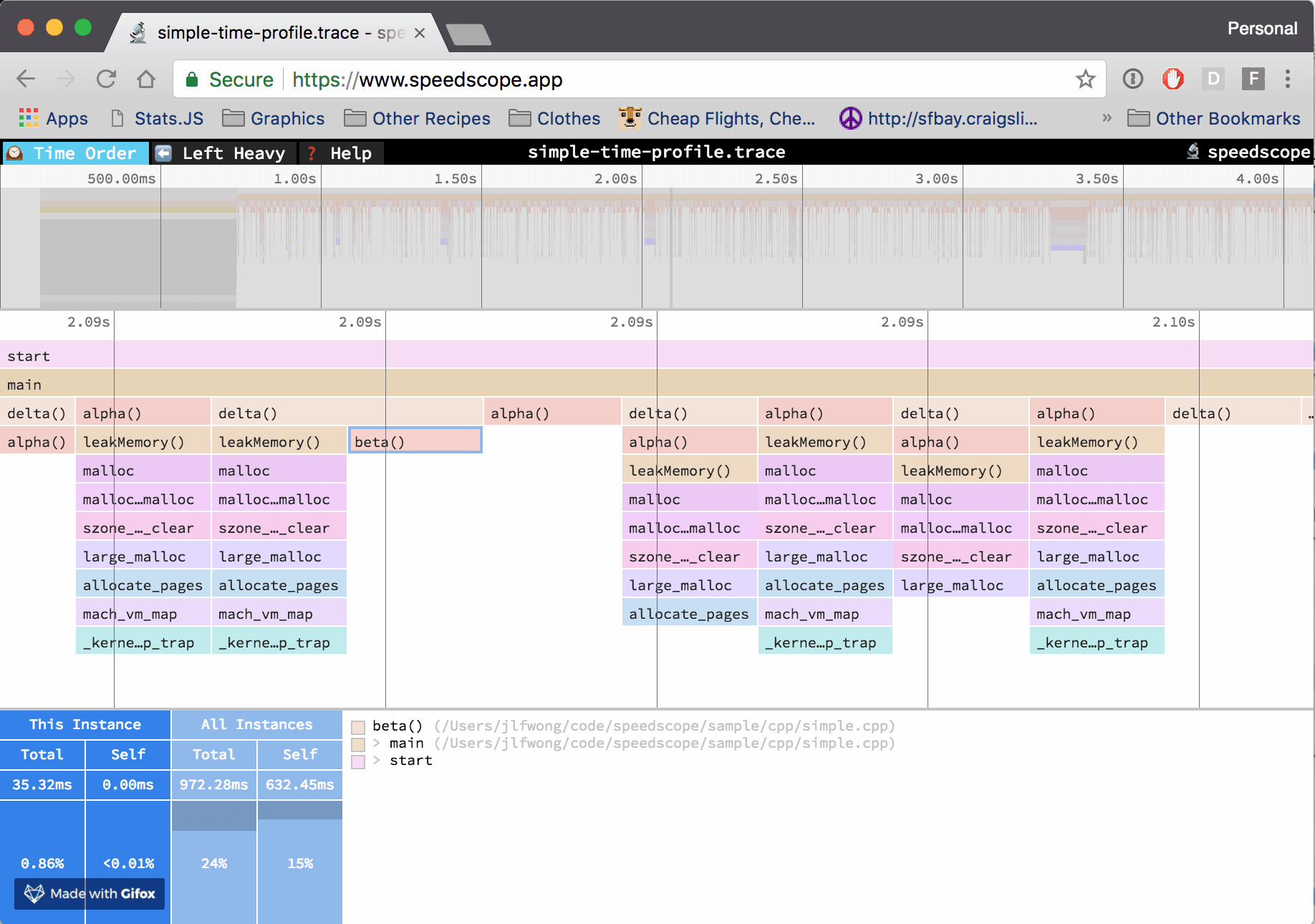
🕰Time Order
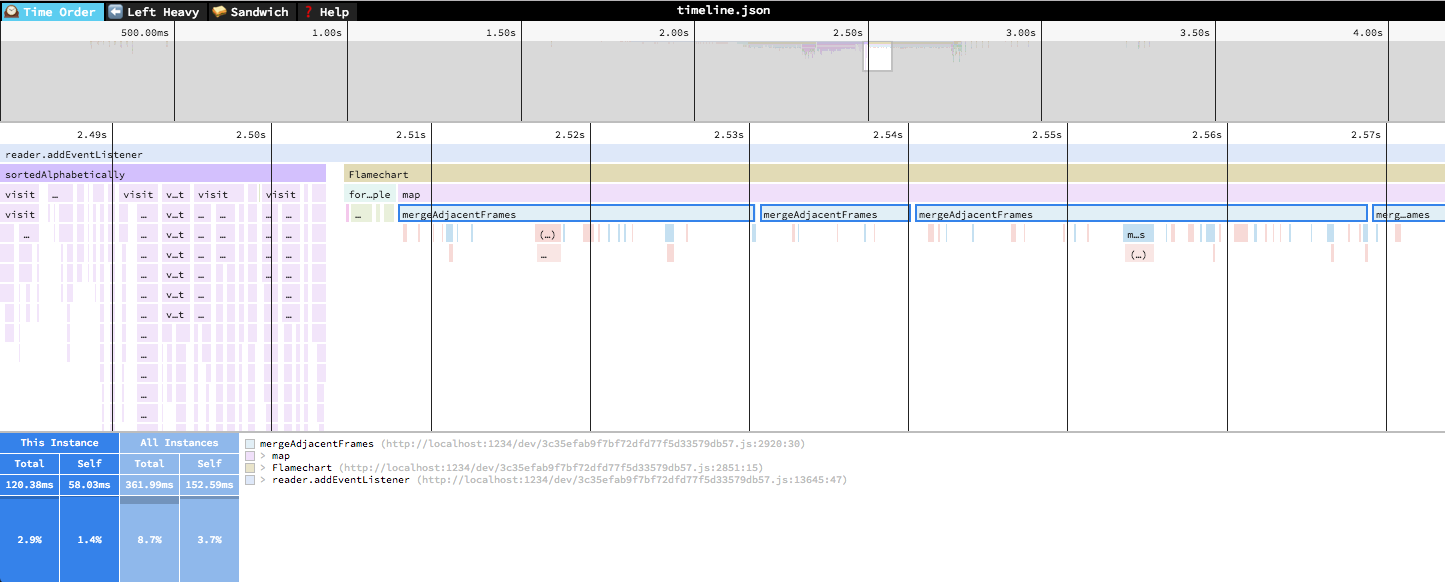
In the "Time Order" view (the default), call stacks are ordered left-to-right in the same order as they occurred in the input file, which is usually going to be the chronological order they were recorded in. This view is most helpful for understanding the behavior of an application over time, e.g. "first the data is fetched from the database, then the data is prepared for serialization, then the data is serialized to JSON".
The horizontal axis represents the "weight" of each stack (most commonly CPU time), and the vertical axis shows you the stack active at the time of the sample. If you click on one of the frames, you'll be able to see summary statistics about it.
⬅️Left Heavy
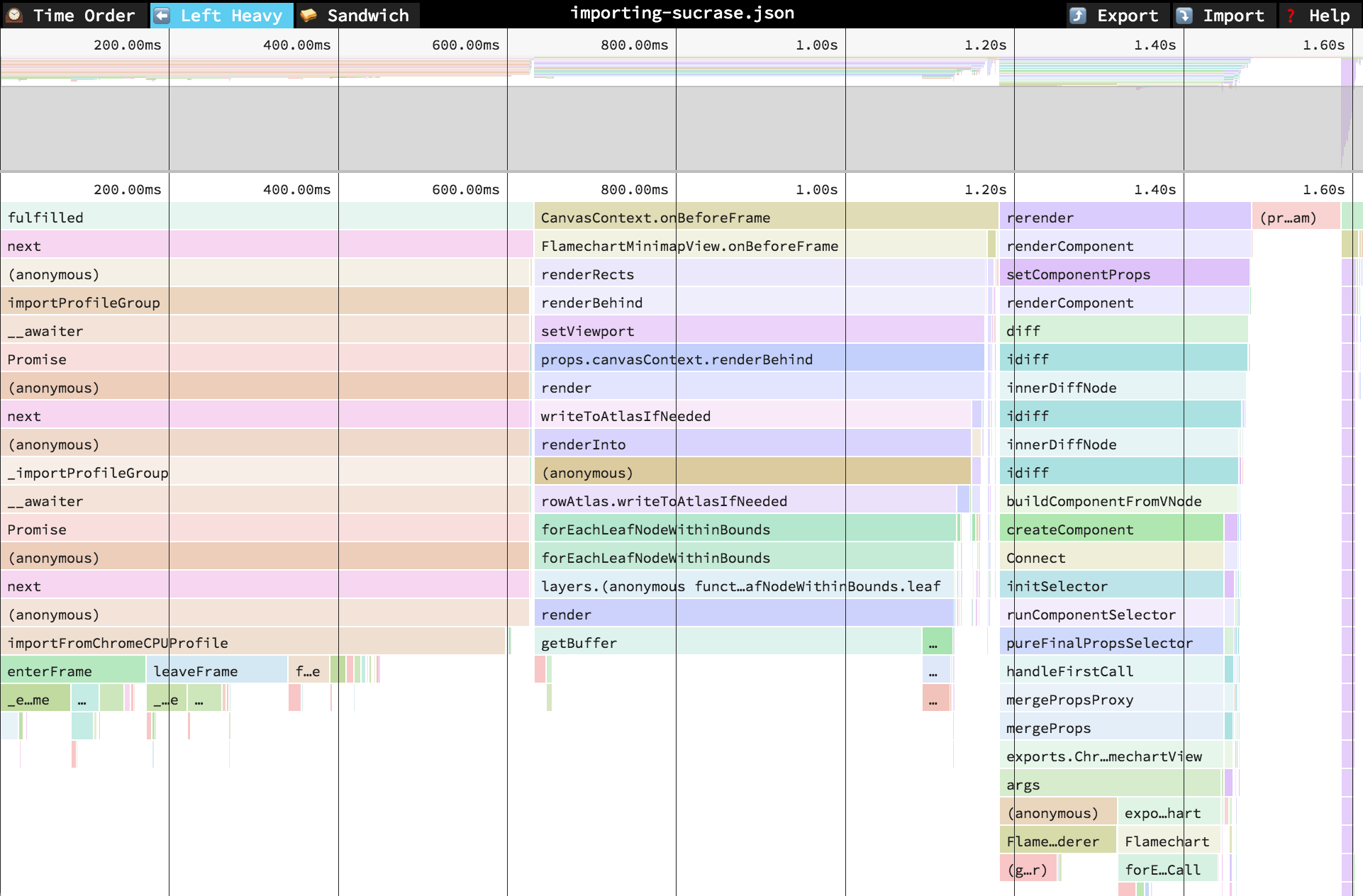
In the "Left Heavy" view, identical stacks are grouped together, regardless of whether they were recorded sequentially. Then, the stacks are sorted so that the heaviest stack for each parent is on the left -- hence "left heavy". This view is useful for understanding where all the time is going in situations where there are hundreds or thousands of function calls interleaved between other call stacks.
🥪 Sandwich
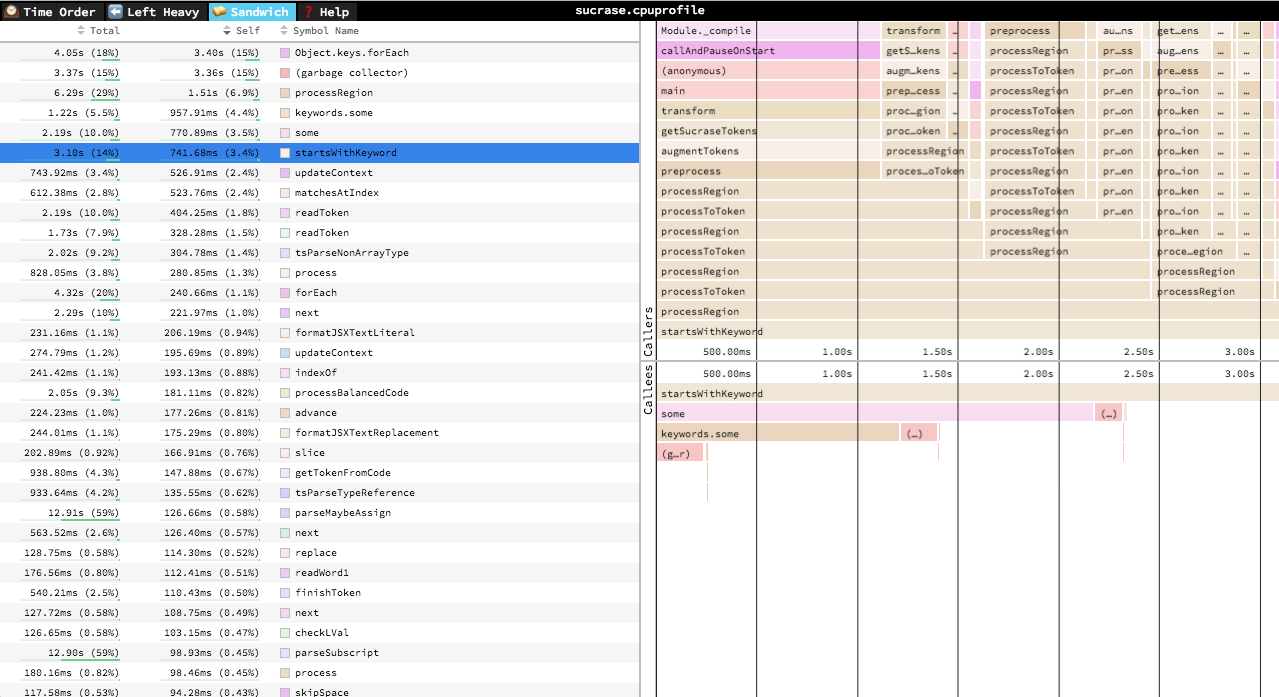
The Sandwich view is a table view in which you can find a list of all functions an their associated times. You can sort by self time or total time. It's called "Sandwich" view because if you select one of the rows in the table, you can see flamegraphs for all the callers and callees of the selected row.
Navigation
Once a profile has loaded, the main view is split into two: the top area is the "minimap", and the bottom area is the "stack view".
Minimap Navigation
- Scroll on either axis to pan around
- Click and drag to narrow your view to a specific range
Stack View Navigation
- Scroll on either axis to pan around
- Pinch to zoom
- Hold Cmd+Scroll to zoom
- Double click on a frame to fit the viewport to it
- Click on a frame to view summary statistics about it
Keyboard Navigation
+: zoom in-: zoom out0: zoom out to see the entire profilew/a/s/dor arrow keys: pan around the profile1: Switch to the "Time Order" view2: Switch to the "Left Heavy" view3: Switch to the "Sandwich" viewr: Collapse recursion in the flamegraphsCmd+S/Ctrl+Sto save the current profileCmd+O/Ctrl+Oto open a new profilen: Go to next profile/thread if one is availablep: Go to previous profile/thread if one is availablet: Open the profile/thread selector if availableCmd+F/Ctrl+F: to open search. While open,EnterandShift+Entercycle through results
Contributing
Do you want to contribute to speedscope? Sweeeeet. Check out CONTRIBUTING.md for instructions on setting up your dev environment.